
In my last post, “Making Modernism Big,” I ended by asking how a computer might read modernism. During the last few months, this question has informed the work I’ve been doing with computer scientist, Belaid Moa. In preliminary attempts to articulate an answer, Belaid and I have been exploring what is possible with Python, a flexible, extensible, and high-level programming language that allows us to give instructions to the computer, essentially teaching it how to read.
Using the texts of Virginia Woolf, Belaid and I are focused on a rather basic computational practice: counting. The computer excels at counting what it reads. Our computer—with the help of Python, Beautiful Soup (a machine parser), and a few regular expressions—can now count the highest frequency of words from The Voyage Out to Between the Acts, or the number of questions in each (805 in The Voyage Out, 473 in Between the Acts). It can find the frequencies of first words in each sentence of The Waves, or the last words. It can find the frequencies of words per HTML-encoded paragraph in Mrs. Dalloway (she, 6; she, 3; the, 10; a, 2; said, 3; etc.). The computer is eager to quantify, and this is great if we find value in knowing the numbers. But to what extent are the numbers important to human readers? Counting the word “war” in Virginia Woolf will not give us much insight into, say, the ways war and gender intersect in Mrs. Dalloway. At least for humans, counting indeed plays a small part in the usual sitting-down-with-a-book reading experience. While we might unconsciously register a repeated word or phrase, it is highly unlikely that anyone will count them as they go.
Still, there is something eerily fascinating about the high-frequency, small words that now captivate our learning computer. These are the words that will likely be most common for any text written in English. It would probably be hard to distinguish between modernist texts, or indeed any group of texts, based on these kinds of results. When thinking about machine learning, these filler words are important because they are usually the easiest to predict. Consider this beginning: “Mrs. Dalloway said she would buy…” Even if you (the human reader) weren’t familiar with the first line, there is a much higher chance you could predict the word that immediately follows (“the”) than the one that comes after that (“flowers”). Predictability is a key part of reading. However, knowing what to predict, a good reader can focus on the parts that are surprising and unpredictable. These small words might signal a kind of architectural structure around which the distinguishing features of literary edifices are often built. Thus, it might be productive to explore not only the ways modernist writers break this edifice apart but also how they reinforce familiar or predictable forms of language.
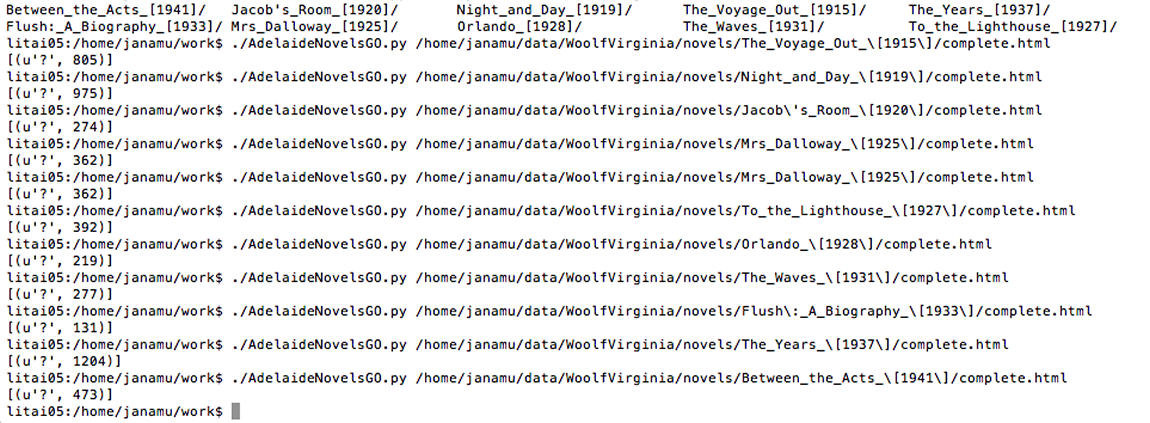
Question Frequencies in Woolf Novels
Going forward we are planning to use Python and other programming languages to further explore (un)predictability, with hopes of teaching our computer to recognize the giddy, exhilarating “plunge” of modernist language.
Post by Jana Millar-Usiskin in the ModVers category, with the versioning tag. Images for this post care of Jana Millar-Usiskin.