
This semester, with the Modernist Versions Project and the Maker Lab, Belaid Moa (Compute Canada) and I have been topic modelling modernist texts. In doing this work, we are hoping to identify heretofore unidentified patterns, both thematic and stylistic, across a (for now, admittedly small) corpus of modernist texts.
Topic modelling assumes authors create documents using collocated clusters of words. By working “backward,” computer algorithms sort the words from a set of pre-processed documents and generate lists of words that comprise these clusters. In our work, we are using the LDA (Latent Dirichlet Allocation) probabilistic model. This rather popular model operates on the Bayesian method of inference, a mathematical concept that works backward from an observed set of data to calculate the probability of certain conditions being in place in order to produce that set of data. In other words, it depends on a notion of causality and asks what circumstances need to be in place in order for certain results to occur.
Using the MALLET package (an open source application developed primarily by Andrew McCallum at the University of Massachusetts at Amherst) allows for the implementation of Gibbs sampling, parameter optimization, and tools for inferring topics from trained models. These affordances let the researcher alter the distribution of topics across documents, and the distribution of words across topics. That is, we can adjust our model to achieve more interesting results. We are interested in a model that is, as Julia Flanders describes it, a “strategic representation,” which might “distort the scale so that we can work with the parts that matter to us” (“The Productive Unease of 21st-century Digital Scholarship”).
For the purposes of our very preliminary study, we are examining word trends across a corpus but also, at least to some extent, narrative tendencies. In so doing, we employed MALLET’s stop words list, which allows the algorithm to ignore common “function words” (i.e., adverbs, conjunctions, pronouns, and propositions). The idea is to eliminate words that carry little thematic weight. Following a method outlined by Matthew Jockers and advocated by Belaid Moa, we also removed character names where possible. While it would likely be interesting to look at the ways MALLET reads texts without any intervention, for our purposes character names made it harder to express tendencies across the novels. However, we did not employ Jockers’s method in its entirety. In some cases, he uses a noun-based approach, eliminating all parts of speech except for nouns. But we felt that, at least for now, including verbs and adjectives was important for revealing aspects of narrative. Jockers also advocates chunking texts, but we were interested in the ways the algorithm would read entire novels as documents.
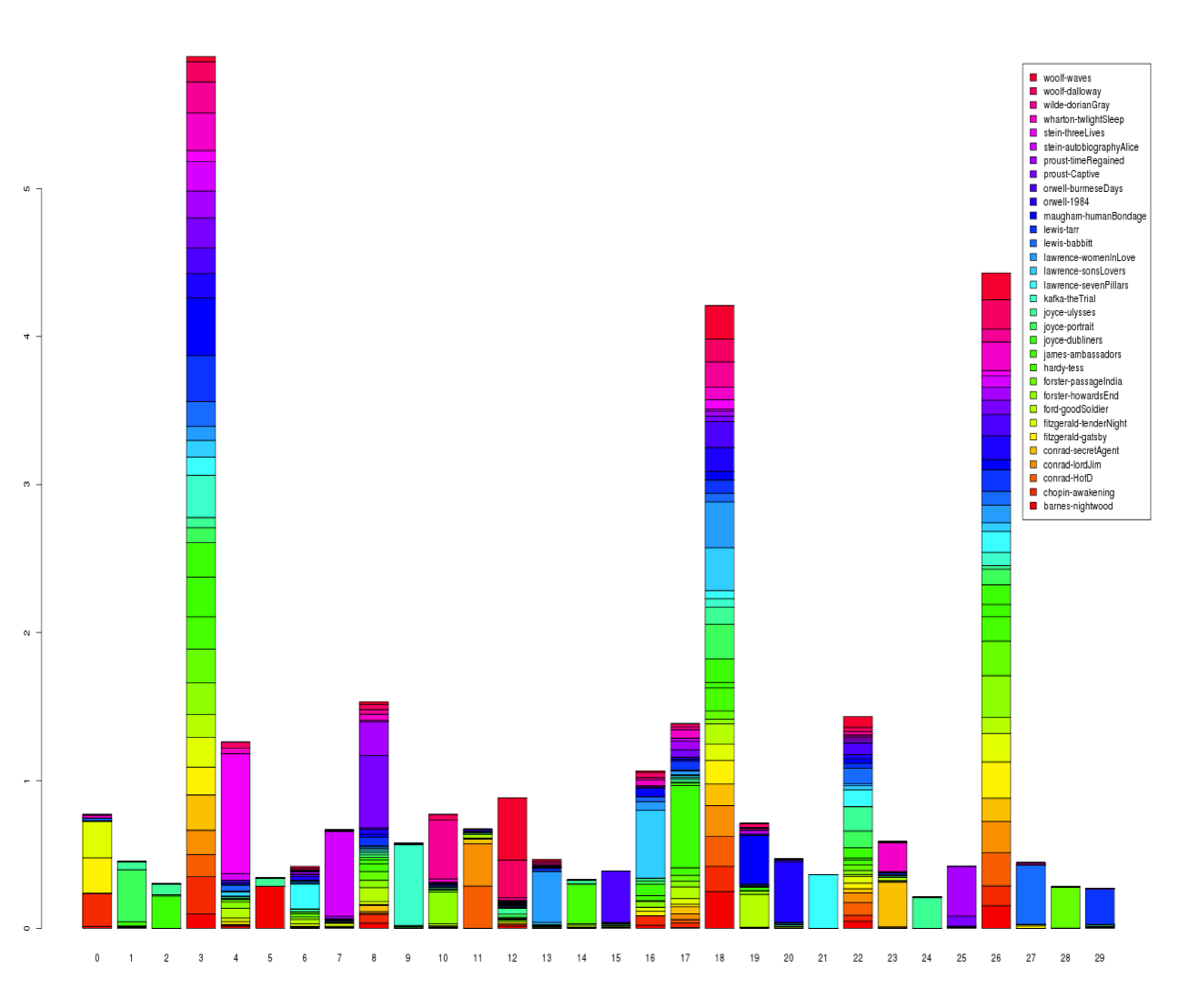
While our repository of modernist texts has been growing, we limited this preliminary study to a corpus of thirty-two early twentieth-century texts, formatted as TXT files, to come up with a profile of the most prominent topics identified by LDA. The algorithm is interested in finding the topics that can be used to correlate all the texts as well as the topics that can be used to distinguish between individual texts. The top three topics that are evenly distributed throughout the corpus—here showing the first nine words—are:
time, felt, day, looked, knew, work, face, hand, night
eyes, face, life, time, white, dark, round, hand, head
men, people, began, room, house, talk, suddenly, end, years
When reading these topics, we might want to consider that, according to the algorithm, these words are not only more frequent within the corpus, but have a greater chance of appearing near each other. As well, the top three or four words are considerably more heavily weighted than later words. Unsurprisingly, time seems to play a significant role in all the categories. Thus we might ask how categories each tell us something unique about time and temporality. In the first topic, the verbs are all in the past tense. Notably, the second topic arguably contains no verbs, with “face,” “hand”, “eyes,” and “head” possibly being exceptions. The fragmented body parts also reveal an interesting slippage between time embodied in humans and time embodied in objects. For instance, as Stephen Ross notes, the results do not distinguish between the face or hand of a clock and the face or hand of a human character. The third category suggests that critics might want to consider how the durations of events (especially their beginnings and endings) are situated, and how spatiotemporal concepts shift across texts. For instance, when and where do people become men? Or do houses and rooms become years?
MALLET also shows us the relative weight of these word collocations across the novels.
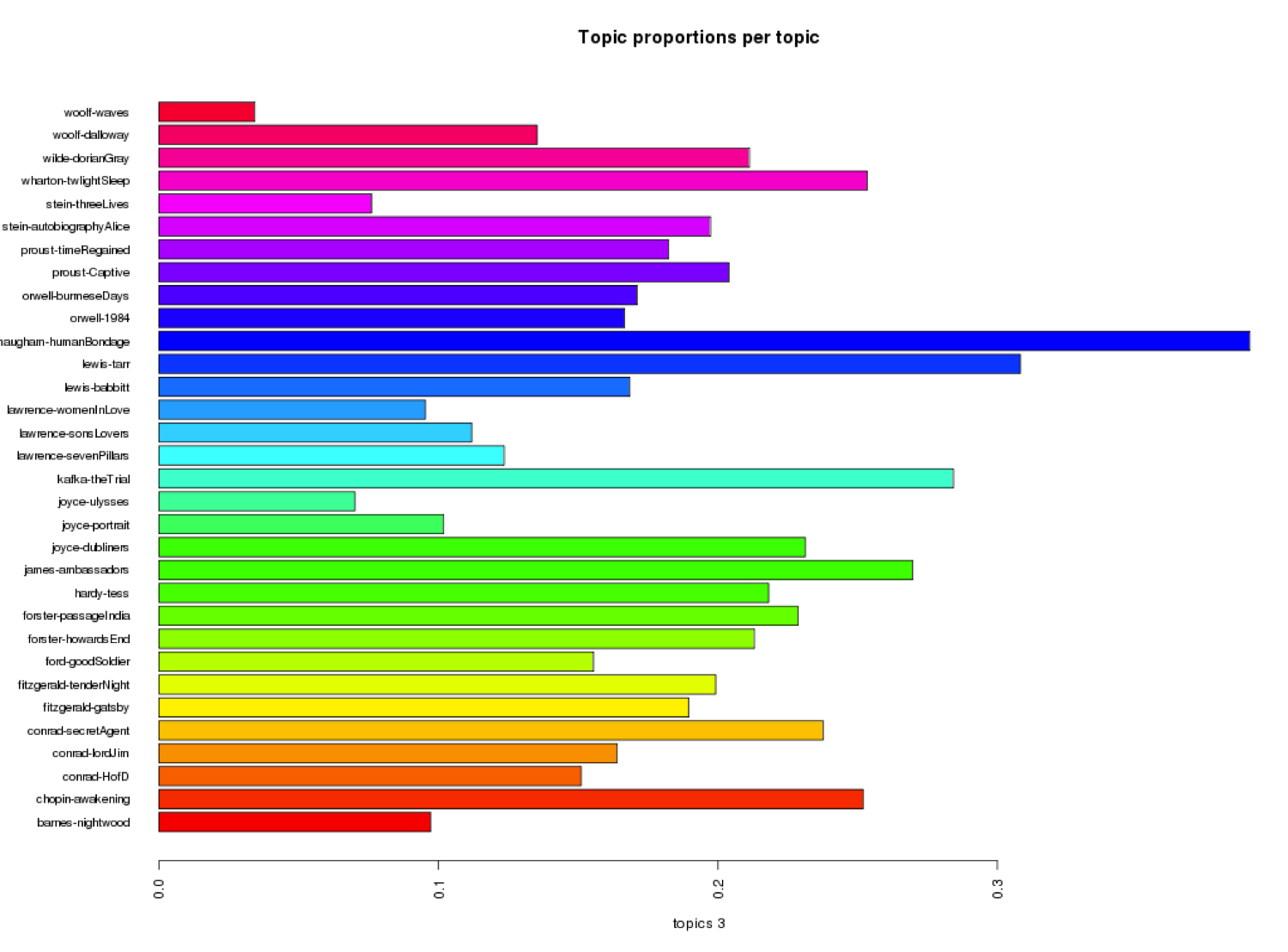
Temporality Past
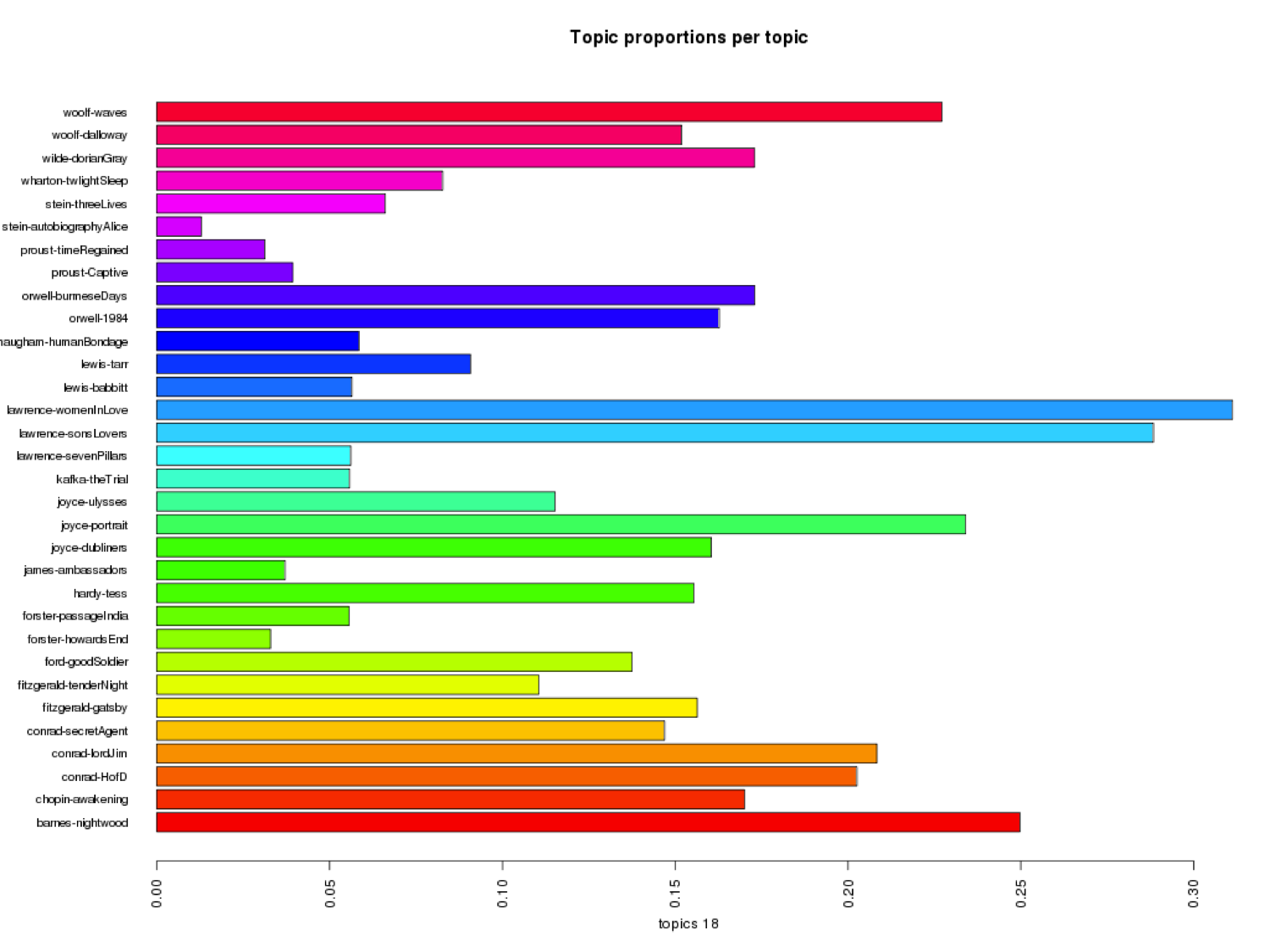
Temporality Embodied
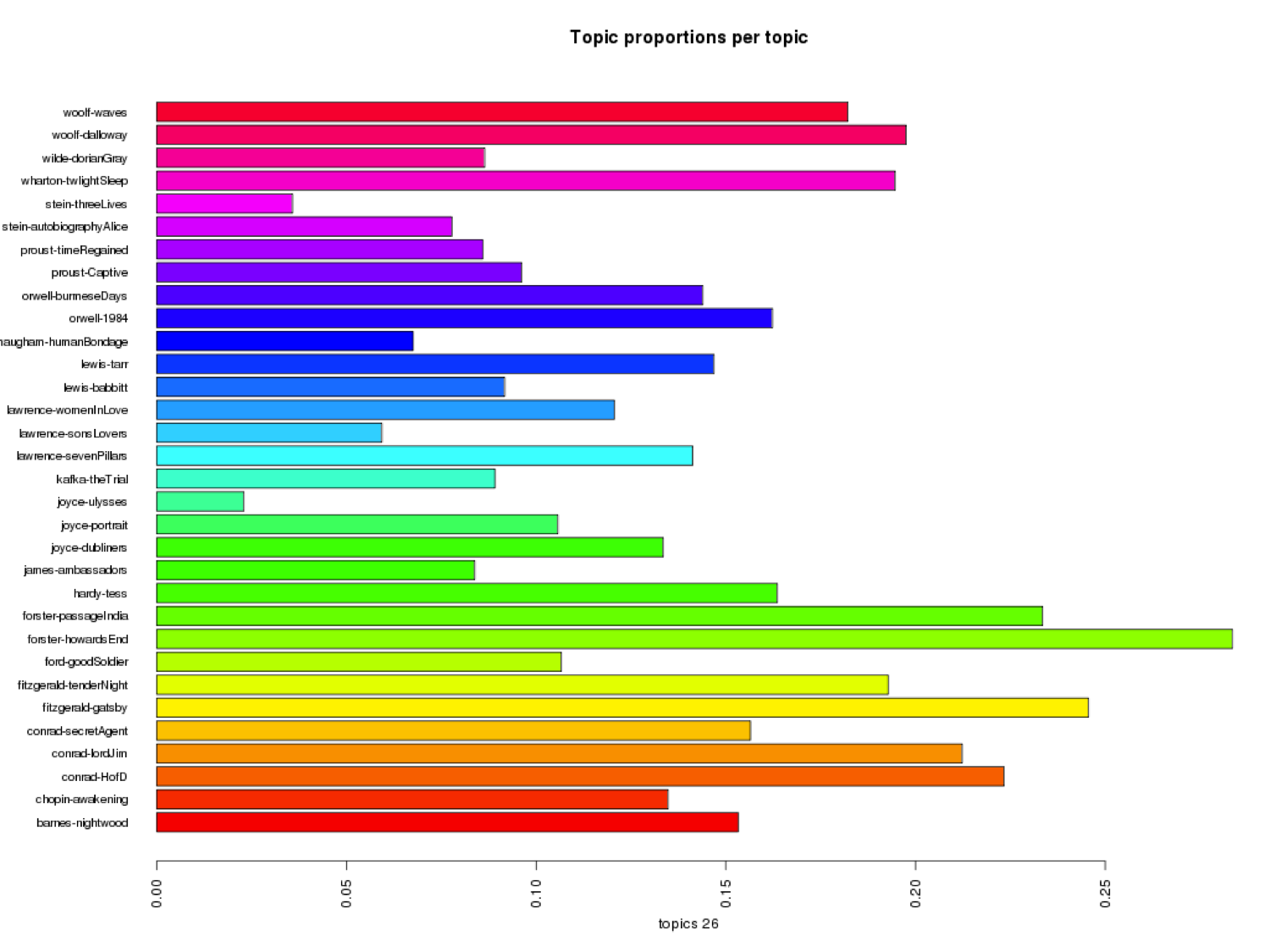
The Temporality of Place
The third category, labelled “The Temporality of Place,” appears more prominently in Howard’s End, Mrs. Dalloway, A Passage to India, The Great Gatsby, and Heart of Darkness. We might ask how these texts in particular focus on the temporality of particular physical environments. On the other hand, I wonder why The Waves, Ulysses, and Women in Love do not seem to engage as fully with the first category, labelled “Temporality Past.” We might also ask how the novels of D. H. Lawrence seem to best exemplify the second category, labelled “Temporality Embodied.” Through LDA, do we get any sense of overlap between the ways people and objects embody time?
Building on MALLET’s algorithms, Belaid Moa has also written scripts that allow us to cluster texts according to perceived similarities and differences. Many readers will notice that Howard’s End and Mrs. Dalloway are similar when it comes to “The Temporality of Place,” but that topic 12 (people street feel leaves trees window room green door) is considerably more prevalent in Mrs. Dalloway than in Howard’s End. Moa’s script projects all these differences and similarities and allows us to see the texts clustered according to MALLET’s assigned topics.

The Multiple Dimensions of Topics in Modernism
Given our current data set, these are the clusters we identified with LDA, with the exemplar being the text most central to that particular cluster:
Cluster 1, exemplar Tender is the Night:
The Awakening (Chopin), Heart of Darkness (Conrad), Lord Jim (Conrad), The Secret Agent (Conrad), The Great Gatsby (Fitzgerald), Tender is the Night (Fitzgerald), The Trial (Kafka), Babbitt (S. Lewis), Tarr (W. Lewis), 1984 (Orwell), Burmese Days (Orwell), The Autobiography of Alice B. Toklas (Stein), Twilight Sleep (Wharton)
Cluster 2, exemplar Ulysses:
Nightwood (Barnes), A Passage to India (Forster), Tess of the D’Urbervilles (Hardy), The Dubliners (Joyce), Portrait of the Artist as a Young Man (Joyce), Ulysses (Joyce)
Cluster 3, exemplar Seven Pillars of Wisdom:
Seven Pillars of Wisdom (Lawrence)
Cluster 4, exemplar Time Regained:
The Ambassadors (James), The Captive (Proust), Time Regained (Proust)
Cluster 5, exemplar Mrs. Dalloway:
The Good Soldier (Ford), Howard’s End (Forster), Sons and Lovers (Lawrence), Women in Love (Lawrence), Of Human Bondage (Maugham), Three Lives (Stein), The Picture of Dorian Gray (Wilde), Mrs. Dalloway (Woolf), The Waves (Woolf)
What subcategories of early twentieth-century modernism do these clusters suggest? How do we define these clusters for modernist literary criticism? Do they actually suggest anything, including temporal, geographic, or stylistic tendencies? How might these clusters compare with models constructed for, say, Victorian novels? These are questions we are also experimenting with, and we look forward to exploring further as we continue this work.
Post by Jana Millar-Usiskin in the ModVers category with the versioning tag. Images for this post care of Jana Millar-Usiskin.
Pingback: Making Models of Modernism | Modernist Versions Project()